
It’s already been a week since we closed our third annual Chaos Conf! While we were forced to take the conference online, this meant that more of you could join us. Over 3,500 people signed up to help make this the world’s largest Chaos Engineering conference. That’s 5x more than 2019, and nearly 10x more than 2018! This is a testament to the growth of Chaos Engineering as a practice across many different industries and around the world.
While we can’t look back at everything that was presented (this blog would turn into a book), we want to share some of our favorite moments and highlights from some of the talks. You can find all of the talks here.
Highlights
Some of our favorite Chaos Conf moments were the success stories shared by different teams that adopted Chaos Engineering. For a lot of people, reliability isn’t just about keeping servers running. It’s about helping customers and making their lives easier.
One such story is H-E-B, a Texas-based supermarket chain. When H-E-B started building their curbside delivery service, they couldn’t possibly have known a global pandemic would force them to scale their service in just a few short weeks. But that’s exactly what happened. Curbside pickup went from being a “nice-to-have” to a necessity for protecting their customers. Practicing Chaos Engineering with Gremlin helped them roll out and scale their new service with minimal issues, increase their uptime to 99.99%, and give their employees a much healthier work-life balance. Check out his talk, "Stabilizing and Reinforcing H-E-B's Existing Curbside Fulfillment Systems While Reinventing Them."
You never know when your pandemic is coming.
Attendees also got a look into how global enterprises use Chaos Engineering with Rahul Arya from JPMC. With over 50,000 engineers and 6,500 applications, he explained how JPMC increased development velocity and reduced deployment times while maintaining strict compliance and security standards. By making Gremlin available to engineers inside new environments, they were able to automate application reliability and let their developers do what they do best: write and deploy code faster. Watch his talk, "Let Devs be Devs."
Folks who have a DevOps mindset…[have a great affinity towards] building for resiliency and building for chaos as code. It’s almost second nature to them.
Lastly, we announced the Gremlin Chaos Champion program, where we spotlight Chaos Engineering practitioners around the world who are helping drive the practice forward. These champions were nominated by their colleagues and managers for the work they’ve done onboarding new teams on Gremlin, running GameDays, integrating Gremlin within their CI/CD pipelines, and making reliability a central tenet of their job function. Congratulations to Chaitanya Krant, Jenn Riemer, Adam Margherio, and Matthew Simons!
The Chaos Conf story
Each day of Chaos Conf was focused on one aspect of reliability preparation. Together, they told a complete story from identifying the need for reliability to implementing Chaos Engineering in your organization.
The “why” has always been reliability
Chaos Conf kicked off with Gremlin’s CEO and Founder, Kolton Andrus, who explained why we do what we do. Modern systems are becoming more complex and have more unknown variables and failure modes than before. We need a way to find and address these failure modes.
The “why” is making our systems more reliable, and the “how” is Chaos Engineering.
Matt Simons from Workiva echoed this by talking about the end of the full stack engineer. No one person can fully understand a modern system from top to bottom. At the same time, we need these systems to operate reliably and predictably, even during unpredictable events.
As we increase complexity in our systems, the predictability of those systems goes down. Products are black holes for complexity: they accrete complexity without end.
Making a business case for Chaos Engineering
The value of reliability and Chaos Engineering isn’t always apparent to businesses. Sometimes we need to prove the value to managers and leadership before we can start working on reliability. Honeycomb’s Liz Fong Jones suggests using past incidents that caused you to miss your service level objectives (SLOs) as an argument for greater reliability.
This sparked conversation in the Chaos Conf Slack, with attendees explaining how it’s not enough to convince senior management, but also engineers and engineering leadership. Some found success by taking high-level DevOps metrics and breaking them down into meaningful insights, making them regularly visible, and discussing them during team meetings. This showed the effectiveness of Chaos Engineering and helped convince engineers through tangible results, creating a positive feedback loop.
Starting on your Chaos Engineering journey
Many speakers shared their experiences and insights with using Chaos Engineering at their companies. We were thrilled to have the legendary Adrian Cockcroft talk about "Failing Over without Falling Over," where he presented the Systems Theoretic Process Analysis (STPA) model and how it can be used to identify failure points between applications, automation, and the humans controlling these systems. He also used the analogy of building resilient systems like a rope, not a chain; chains are only as strong as their weakest link, but ropes have multiple strands and provide a margin of safety before failing.
Good cloud resilience practices should include chaos first.
When starting your Chaos Engineering journey, it’s important to know how your systems behave under normal conditions. In his talk "The More You Know: A Guide to Understanding your Systems," Twilio's Tyler Wells offered a guided tour on getting to know your systems using observability, synthetic testing, and GameDays. There was so much excitement around this template that Twilio immediately open-sourced it! You can find their template on GitHub.
To know your systems is to love your users!
Implementing Chaos Engineering as a practice
Once you identify the need for Chaos Engineering, how do you implement and promote it within your organization?
Doug Campbell offers some insights from Grubhub. Building off of the idea that “developers know their services best,” Grubhub introduced Chaos Engineering to engineers who were already interested in using the tools. He explained how they rolled out Gremlin to all engineers and all systems simultaneously, allowing anyone to run attacks on all services. But by trusting engineers to inform each other, communicate, and accept the risks that came with experimentation, they were able to drive adoption and bake Chaos Engineering into engineers’ workflows.
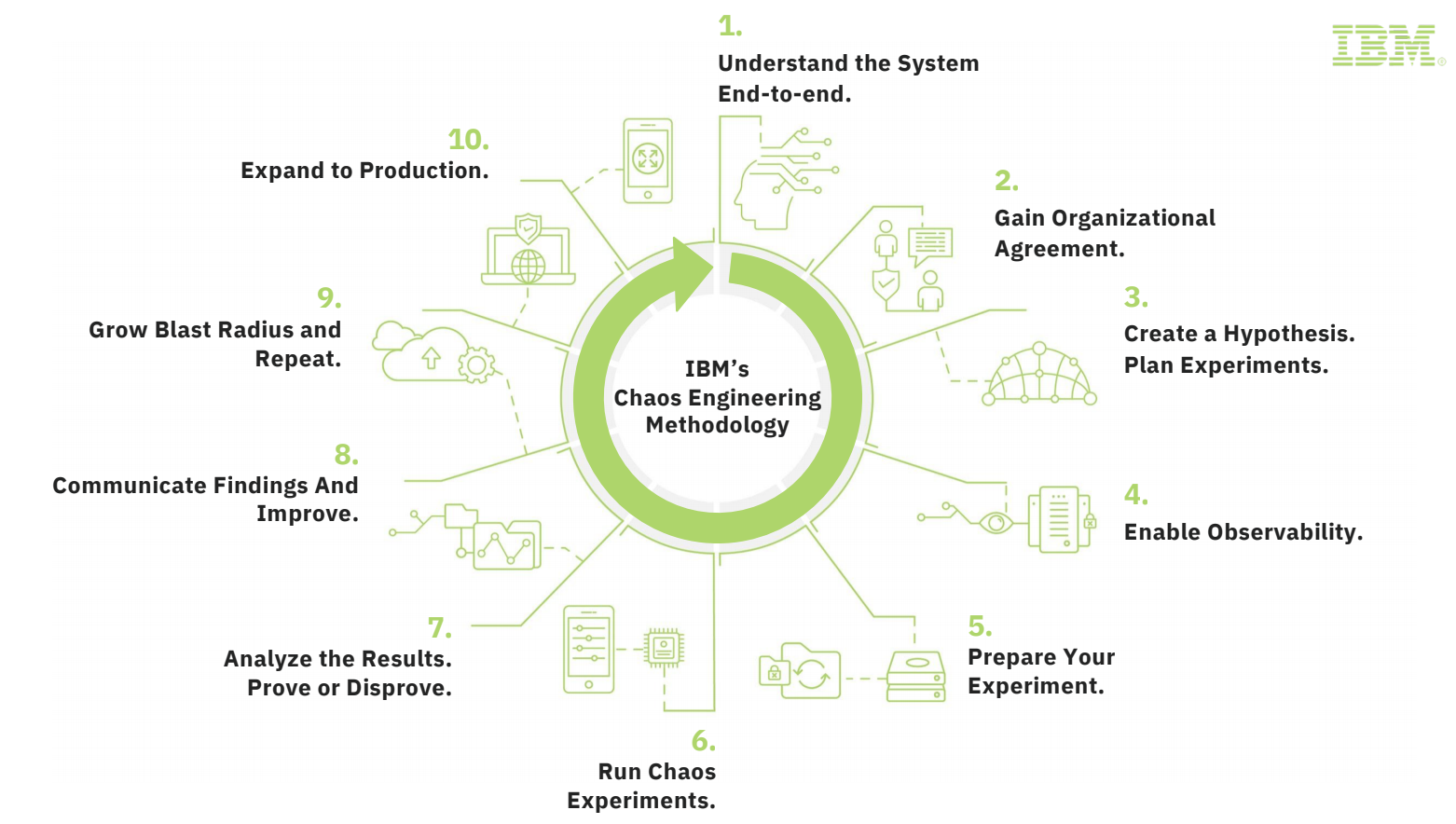
Once you’ve implemented Chaos Engineering, how do you know what experiments to run? IBM’s Haytham Elkhoja presented the F5s: fires, floods, fools, and fat-fingers. Their applications must be resilient to disasters (fires and floods), SREs who don’t follow operating procedures (fools), and accidents (fat-fingers). Haytham presented IBM’s eight principles of Chaos Engineering and ten-part methodology, which include experimenting across all their components as close to production as possible, and constantly communicating findings between teams.
Scaling a culture of resiliency
Building a culture of reliability can be hard, especially in large, enterprise companies. Nate Vogel shared his story of building a stable data platform used internally by other teams at Charter, and the challenges he faced with sudden growth within the company. It’s not enough to get all levels of leadership onboard from the executive level down to the team manager level. As the company grows, we need to continuously promote a culture of reliability, innovation, and our core values among our engineers.
Resiliency means being fallible, but in a trustworthy way.
Stay involved!
Thank you to our partners for helping make this event successful, as well as our speakers for sharing their expertise. Thank you to the Gremlin team for dedicating countless hours towards making this event happen, from our heroic event organizer to our amazing MCs and everyone working behind the scenes. And finally, thank you to the Chaos Engineering community! This conference wouldn’t be what it is without you!
There were so many great moments and insights that we weren’t able to capture in this one blog post. Make sure to check out all of the talks here.
Chaos Conf might be over, but reliability is ongoing. Stay involved by joining the Chaos Engineering Slack and learning more about Chaos Engineering. Thanks for joining us, and stay safe!

